

- Alexa! Turn on the Lights.
- OK Google! call Mom.
- Hey Siri! Take a picture.
- . . .
You’ve probably interacted with speech recognition technology in some form, whether it’s through a virtual assistant or voice-controlled device. These tools use a series of steps to interpret and respond to your spoken commands. In this post, we’ll take a look at the history of speech recognition and how it has evolved over time. We’ll also delve into the technical details of how speech recognition works and explore some of the latest and most exciting applications of this technology. .
1. A run back to history
Speech recognition technology has come a long way since the days of Alexander Graham Bell and other inventors experimenting with voice-controlled devices in the late 1800s. It wasn’t until the middle of the 20th century that speech recognition technology began to be developed for practical use. Early speech recognition systems had a limited vocabulary and required users to speak in a very clear and controlled manner. The first successful continuous speech recognition system was created in the 1970s by a team at IBM, which could recognize a vocabulary of over 1,000 words.
As technology progressed, speech recognition continued to improve in the 1980s and 1990s, with larger vocabulary systems and the ability to recognize continuous speech. With the advent of more powerful computers and the growth of the internet, speech recognition technology became more widely available and began to be integrated into a variety of applications such as voice-controlled personal assistants and automated customer service systems.
Fast forward to today, speech recognition technology is more advanced than ever, able to recognize a wide range of accents, dialects, and languages. It’s used in a wide range of applications, including virtual assistants, voice-controlled devices, and speech-to-text software and continuously improving to become more accurate, natural, and user-friendly.
The summary of the evolution of the speech recognition carrier is presented in the figure down below.
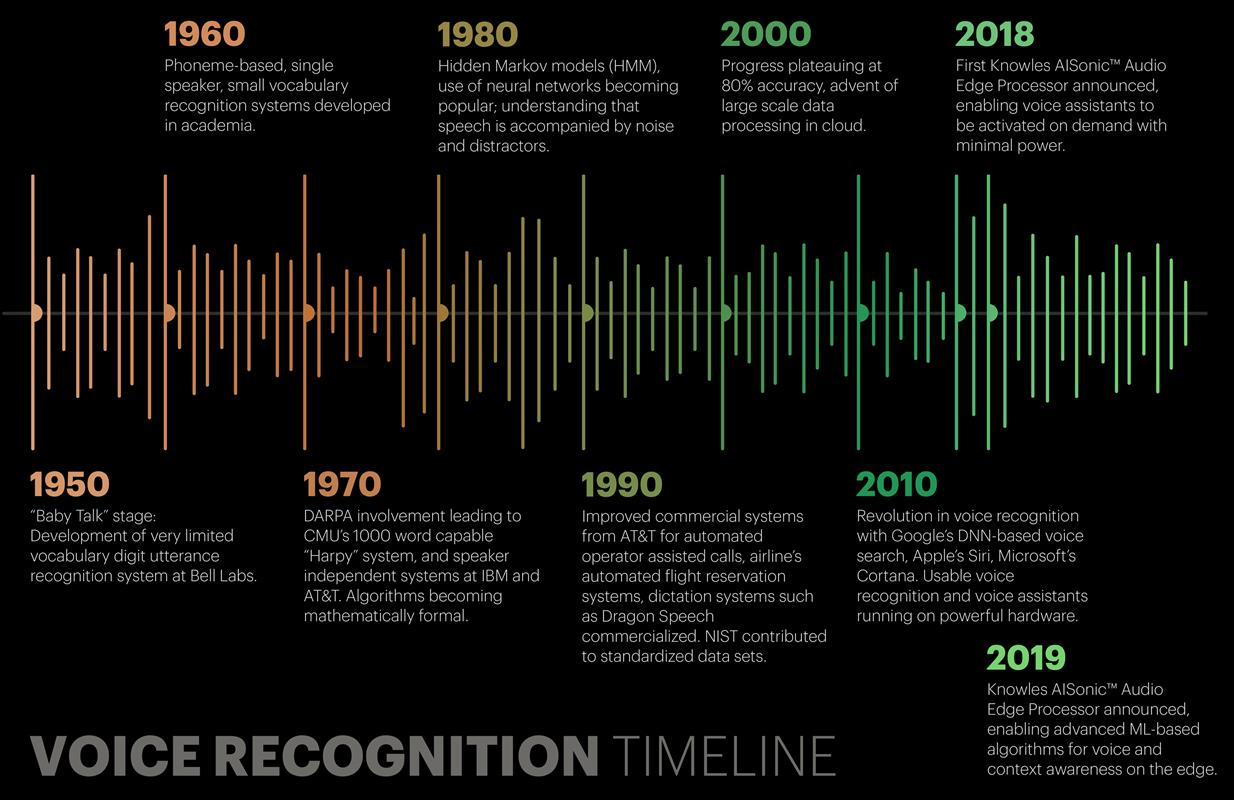
- The first speech recognition system, Audrey, was developed back in 1952 by three Bell Labs researchers. Audrey was designed to recognize only digits
- Just after 10 years, IBM introduced its first speech recognition system IBM Shoebox, which was capable of recognizing 16 words including digits. It could identify commands like “Five plus three plus eight plus six plus four minus nine, total,” and would print out the correct answer, i.e., 17
- The Defense Advanced Research Projects Agency (DARPA) contributed a lot to speech recognition technology during the 1970s. DARPA funded for around 5 years from 1971–76 to a program called Speech Understanding Research and finally, Harpy was developed which was able to recognize 1011 words. It was quite a big achievement at that time.
- In the 1980s, the Hidden Markov Model (HMM) was applied to the speech recognition system. HMM is a statistical model which is used to model the problems that involve sequential information. It has a pretty good track record in many real-world applications including speech recognition.
- In 2001, Google introduced the Voice Search application that allowed users to search for queries by speaking to the machine. This was the first voice-enabled application which was very popular among the people. It made the conversation between the people and machines a lot easier.
- By 2011, Apple launched Siri that offered a real-time, faster, and easier way to interact with the Apple devices by just using your voice. As of now, Amazon’s Alexa and Google’s Home are the most popular voice command based virtual assistants that are being widely used by consumers across the globe.
2. What’s Speech ?
Speech refers to the verbal communication of words, thoughts, and ideas through the use of sounds. It is the process of producing audible words and sentences by using the voice and articulating sounds with the mouth, throat, and lungs. Speech is a fundamental aspect of human communication and is used in a wide range of contexts, including conversation, public speaking, and broadcasting. It is a complex process that involves the coordination of various cognitive, linguistic, and physiological processes, such as phonation, articulation, and prosody.
Here is for example the speech recording in an audio editor.
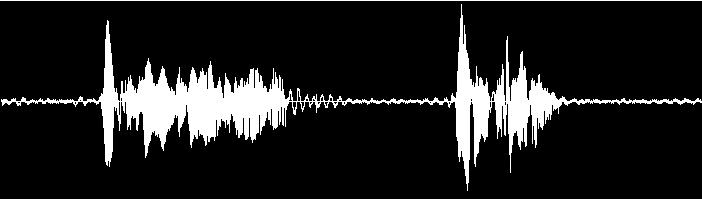
All modern descriptions of speech are to some degree probabilistic. That means that there are no certain boundaries between units, or between words.
3. Speech Recognition process
According to the speech structure, three models are used in speech recognition to do the match:
- An acoustic model contains acoustic properties for each senone. There are context-independent models that contain properties (the most probable feature vectors for each phone) and context-dependent ones (built from senones with context).
- A phonetic dictionary contains a mapping from words to phones. This mapping is not very effective. For example, only two to three pronunciation variants are noted in it. However, it’s practical enough most of the time. The dictionary is not the only method for mapping words to phones. You could also use some complex function learned with a machine learning algorithm.
- A language model is used to restrict word search. It defines which word could follow previously recognized words (remember that matching is a sequential process) and helps to significantly restrict the matching process by stripping words that are not probable. The most common language models are n-gram language models–these contain statistics of word sequences–and finite state language models–these define speech sequences by finite state automation, sometimes with weights. To reach a good accuracy rate, your language model must be very successful in search space restriction. This means it should be very good at predicting the next word. A language model usually restricts the vocabulary that is considered to the words it contains. That’s an issue for name recognition. To deal with this, a language model can contain smaller chunks like subwords or even phones. Please note that the search space restriction in this case is usually worse and the corresponding recognition accuracies are lower than with a word-based language model.
Those three entities are combined together in an engine to recognize speech. If you are going to apply your engine for some other language, you need to get such structures in place. For many languages there are acoustic models, phonetic dictionaries and even large vocabulary language models available for download.
The process of speech recognition involves several steps:
- Speech Acquisition: The first step is to acquire the speech signal, typically by using a microphone to convert sound waves into an electrical signal.
- Pre-processing: The next step is to pre-process the speech signal by removing noise, normalizing the volume, and removing any unwanted background noise.
- Feature Extraction: In this step, the speech signal is analyzed and a set of features are extracted, which can be used to represent the speech signal. These features can include information about the pitch, energy, and frequency of the speech signal.
- Modeling: The next step is to create a model of the speech signal, typically using machine learning algorithms. This model can be used to recognize speech patterns and identify specific words or phrases.
- Decoding: The final step is to use the model to decode the speech signal and convert it into text. This can be done using a variety of techniques, such as statistical language modeling or neural network-based approaches.
- Post-processing: In this step, the decoded text is post-processed to remove any errors and to improve its overall accuracy.
It’s worth mentioning that these steps can vary depending on the specific application and the type of speech recognition system being use
4. Speech Recognition Libraries
Speech recognition technology has come a long way in recent years, making it easier for developers to integrate voice commands and dictation into their applications. There are several libraries available for speech recognition, each with its own set of features and capabilities.
- CMU Sphinx: This open-source library is written in Python and C, and is widely used for speech recognition in embedded systems and mobile devices. It supports a variety of languages and can be trained to recognize specific words and phrases.
- Kaldi: Developed by researchers at the University of California, Berkeley, Kaldi is an open-source library that is widely used in the speech recognition research community. It supports a wide range of languages and can be used to train models for both isolated and continuous speech recognition.
- Google Speech-to-Text API: This cloud-based service from Google allows developers to convert audio to text in a variety of languages. It offers advanced features such as speaker diarization and automatic punctuation.
- Microsoft Azure Speech Services: This cloud-based service from Microsoft provides a wide range of speech recognition and synthesis capabilities, including support for multiple languages and the ability to transcribe spoken words into text in real-time.
- Amazon Transcribe: This cloud-based service from Amazon allows developers to convert speech to text in a variety of languages. It also provides a number of advanced features, such as speaker recognition and support for multiple channels. OpenVINO: This is an open-source toolkit from Intel that allows developers to optimize pre-trained models for a variety of platforms, including embedded devices and edge devices. It supports a wide range of frameworks, including TensorFlow and Caffe, and can be used for both speech recognition and computer vision tasks.
- SpeechRecognition: This is a Python library for performing speech recognition, with support for several engines and APIs, including Google Speech Recognition, Microsoft Bing Voice Recognition, and Google Cloud Speech API. It is easy to use and can be integrated into a variety of applications.
- Mozilla DeepSpeech: This is an open-source deep learning-based engine for speech recognition developed by Mozilla. It can be used to train models on a variety of languages and can be integrated into a wide range of applications, including web browsers and mobile apps.
- PyTorch-Kaldi: This is an open-source project that combines the PyTorch deep learning framework with the Kaldi speech recognition toolkit. It can be used to train models for a variety of speech recognition tasks, including language modeling and speech-to-text.
- Pocketsphinx: Pocketsphinx is a lightweight speech recognition engine, specifically tuned for handheld and mobile devices, though it works equally well on the desktop. It is a part of the CMU Sphinx Open Source Toolkit For Speech Recognition
In addition to the libraries and frameworks mentioned above, there are many other options available for speech recognition. It is important to note that the best choice for your need will depend on your specific needs and requirements.
5. Speech Recognition Research Projects
Speech recognition is a rapidly advancing field, with new research and developments constantly being made. Some current research projects in the field include:
- End-to-End Speech Recognition: This project aims to develop a fully neural network-based speech recognition system that can directly convert speech to text without the need for separate components such as phoneme recognition or language modeling.
- Multi-language Speech Recognition: Researchers are working on developing speech recognition systems that can accurately recognize speech in multiple languages, allowing for seamless communication across borders.
- Speech Recognition for Noisy Environments: This project aims to improve the performance of speech recognition systems in environments with high levels of background noise, such as crowded public spaces or industrial settings.
- Emotion Recognition in Speech: Researchers are exploring the use of machine learning algorithms to recognize emotions in speech, with the goal of improving human-computer interaction and making it more natural and intuitive.
- Speech Recognition for Low-Resource Languages: This project aims to develop speech recognition systems for languages that have limited resources, such as small corpora or limited language models.
- Speech Recognition for Medical and Healthcare Applications: This project aims to improve the accuracy of speech recognition systems in medical and healthcare settings, such as dictating patient notes or transcribing medical dictations.
These are just a few examples of the many ongoing research projects in the field of speech recognition. The technology is constantly evolving and new breakthroughs are being made regularly. As new technologies and techniques are developed, we can expect to see even more accurate and versatile speech recognition systems in the future.
6. Conclusion
In conclusion, speech recognition is a rapidly evolving field that has the potential to revolutionize the way we interact with technology. From voice-controlled assistants to automated transcription services, the applications of speech recognition are vast and varied. There are a wide range of libraries, frameworks and APIs available for developers to use in their projects. Furthermore, the current research in speech recognition are working on developing more accurate and versatile systems. With the technology continuing to improve and new developments being made regularly, we can expect to see even more innovative and useful applications of speech recognition in the future.